Task: Store all geo-coded tweets from Sweden, in real time.
apt-get install libproj-dev libgdal1-dev
install.packages("rgdal")
apt-get install libgdal1 apt-get --purge remove libproj-dev libgdal1-dev apt-get --purge autoremove
library(rgdal) sweden <- readOGR("sweden-gis-data", layer = "Sweden_municipality07")
apt-get install libgeos-dev
install.packages("rgeos") library("rgeos")
apt-get --purge remove libgeos-dev
install.packages("maptools") library(maptools)
sweden.united <- unionSpatialPolygons(polygons(sweden), rep(1, length(sweden)))
No problem, just give a locations parameter that cover the whole of sweden, and filter out the tweets that falls outside of sweden.
Our object sweden already have an appropriate bounding box that we can use, just transform to longitude and latitude first.
bbox(spTransform(sweden, CRS("+proj=longlat")))
min max
x 11.13373 24.15473
y 55.34008 69.04941
tweets.df <- parseTweets(filterStream(file.name = "", locations = c(11.13373, 55.34008, 24.15473, 69.04941), tweets = 1000, oauth = twitCred), verbose = FALSE)
As it happens, twitter provides a variable "country" that we can filter on, so we do not have to filter by longitude and latitude if we don't want to, we can filter on a country string instead.
Do twitter classify country good enough for us?
sweden.united.longlat <- spTransform(sweden.united, CRS("+proj=longlat")) plot(sweden.united.longlat) these <- which(tweets.df$country == "Sverige") swedes <- SpatialPointsDataFrame(coords = data.frame(tweets.df$place_lon[these], tweets.df$place_lat[these]), tweets.df[these, ], proj4string=CRS("+proj=longlat")) points(swedes@coords, pch = 20) those <- which(tweets.df$country != "Sverige") non.swedes <- SpatialPointsDataFrame(coords = data.frame( tweets.df$place_lon[those], tweets.df$place_lat[those]), tweets.df[those, ], proj4string=CRS("+proj=longlat")) points(non.swedes@coords, pch = 20, col = "red") legend(x = "right", legend = c("Swedish", "not swedish"), col = c("black", "red"), pch = 20)
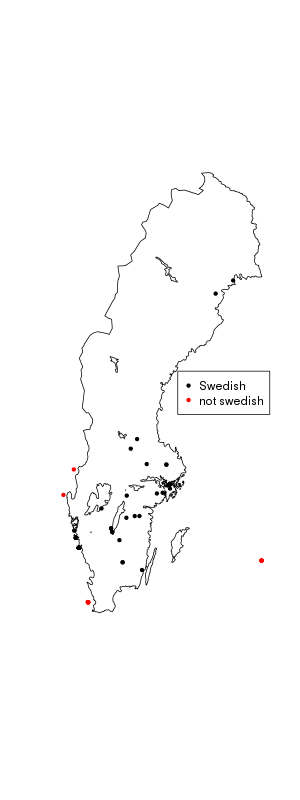
Seems good enough.
swedes.temp.df <- tweets.df[which(tweets.df$country == "Sverige"), ]
library(RMySQL) con <- dbConnect("MySQL", "twitter", username="foo", password="bar") ## Escape chars that have special meaning in SQL with the function dbEscapeStrings() swedes.df <- data.frame(text = dbEscapeStrings(con, swedes.temp.df$text), id = swedes.temp.df$id_str, in_reply_to = swedes.temp.df$in_reply_to_status_id_str, source = dbEscapeStrings(con, swedes.temp.df$source), timestamp = swedes.temp.df$created_at, user = swedes.temp.df$name, latitude = swedes.temp.df$place_lat, longitude = swedes.temp.df$place_lon) ## This assumes there exists a table tweets in the mysql database "twitter" dbWriteTable(con, "tweets", swedes.df, row.names = FALSE, append = TRUE)
To continously capture data, try something like this:
my.twitter.func <- function() { tweets.df <- parseTweets(filterStream(file.name = "", locations = c(11.13373, 55.34008, 24.15473, 69.04941), tweets = 1000, oauth = twitCred), verbose = FALSE) swedes.temp.df <- tweets.df[which(tweets.df$country == "Sverige"), ] swedes.df <- data.frame(text = dbEscapeStrings(con, swedes.temp.df$text), id = swedes.temp.df$id_str, in_reply_to = swedes.temp.df$in_reply_to_status_id_str, source = dbEscapeStrings(con, swedes.temp.df$source), timestamp = swedes.temp.df$created_at, user = swedes.temp.df$name, latitude = swedes.temp.df$place_lat, longitude = swedes.temp.df$place_lon) if(length(grep("tweets", dbListTables(con))) == 0) { ## create the table, run this only once dbWriteTable(con, "tweets", swedes.df, row.names = FALSE) } else { dbWriteTable(con, "tweets", swedes.df, row.names = FALSE, append = TRUE) } } ## Loop indefinately while(TRUE){ my.twitter.func() } ## This might loose a few tweets during the saving to disk procedure, but hey, ## we want the big picture, right?
![[Valid RSS]](valid-rss-rogers.png "Validate my RSS feed")

